Coverage bitmap |
Date | |
|---|---|---|
| Category | Rust |
The decision behind writing this article is simple - I never properly finished my Build simple fuzzer series. Now, after such a long break there is very little sense to continue with it. There is however a certain problem that, left unaddressed, felt like a little thorn in my side. I am speaking about the issued of creating an effective coverage bitmap. Let this article be at least an attempt to tackle it.
In the part 6 of the series I have already explained the topic of the coverage guided fuzzing and there is little point of repeating that. Still, as a brief reminder - we will be using the 64 Kb of shared memory to track all the branches we are hitting. My original approach of incremental counter acting as an index into the bitmap will work for most of the cases because most program tend to stay south of 15,000 branches. If however we end up fuzzing a program that has more than 65,000 branches we will be facing a problem that Terry Pratchett once described as trying to pull a rabbit, size 7 from the hat, size 4.
Before we move further we need to talk what kind of characteristic the good coverage bitmap should exhibit to be well suited for our purpose - accurately tracking the given program execution flow. Among the most important one is the good accuracy, low collision rate, good density and, because we are talking about fuzzing - good performance. We will address those elements as we are moving along with the article.
Before our attempt to design a new system let’s first try to understand how AFL is doing that. The solution is relatively simple (but elegant). Each basic block is assigned a random number - mostly to provide uniform distribution and avoid clustering. While transitioning from block A to block B the corresponding numbers are XORed together and the result is used as a index into the coverage bitmap. With just that approach we would end up with a situation where not only we can’t tell direction of the transition but also all self referencing blocks (or tight loops) would end up pointing at the same index of the bitmap. To solve that AFL replaces the number associated with the previous block using the bit-shifted number associated with the current basic block.
During the development phase of the AFL clang was not supporting the proper coverage interface. Implementing our fuzzer roughly 10 years later has certain advantages. The first one being - we can use SanitizerCoverage instrumentation that already operate on branches, so we do not need to XOR the basic block identifiers. We can simply assign a unique number to each branch and track the hit on our coverage bitmap. That still leaves us with the problem of the bitmap size and using index outside of range.
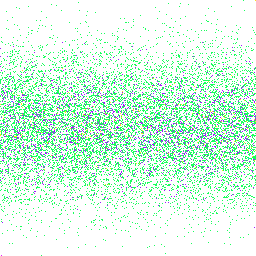
First possible solution is simple - we can assign numbers incrementally and just do the modulo 65536. This will leave us with two problems - structural clustering and the preservation of lower-bit patterns. We can demonstrate the problem with the image.
This is a 256 by 256 bitmap that shows our coverage trace. Each branch index is translated into a two dimensions and each hit is drawn with a different color. Simulating the program execution we can clearly see the clusters of values. The effect here is very visible and shows that results are clustered with upper and lower parts of the image populated very sparsely. If you think this looks like a Gaussian distribution you are absolutely right.
The reason for that is me cheating a little bit. While I was creating a visualization I didn’t wired it up with a real program - instead I have generated 15000 random numbers with the Gaussian distribution and the modulo operation preserved it.
Another example is the bucketing - instead of doing 1:1 mapping we treat every index of the bitmap as a bucket for a group of values. Simply shifting the obtained value 4 bits to the right we get the 1:16 ration so we can fuzz even the most demanding projects. With that we however face a rather serious case of result clustering. We risk many branches ending up in the same bucket skewing our results. Just look at the image.
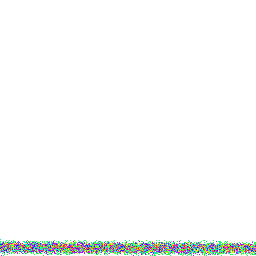
There is a third solution that borrows one element from one famous Italian mathematician. We will be using the Fibonacci golden ration constant that, expressed in hexadecimal format, equals 0x9E3779B9. You can and should read more about it in more reputable sources but, briefly, this number has one important characteristic - great scattering property. If we do multiply incremental numbers by the golden ration the results will be spread around the given space and every consecutive multiplication divides the larges remaining space of the bitmap in half. Image below demonstrates the effect of our new method.

Even with the numbers with the Gaussian distribution all the branches are evenly distributed across our plane.
Now, the code responsible for that is quite simple
#define GOLDEN_RATIO_32 0x9E3779B9
void __sanitizer_cov_trace_pc_guard_init(uint32_t *start, uint32_t *stop) {
if (start == stop || *start) return; // Prevent double-initialization
uint32_t unique_id = 1;
// Assign a pre-computed 16-bit bitmap index to every single guard slot
for (uint32_t *x = start; x < stop; x++) {
uint16_t bitmap_index = (unique_id * GOLDEN_RATIO_32) >> 16;
*x = bitmap_index;
unique_id++;
}
}
Best part is - multiplication with wrapping is very fast on modern CPU (just few cycles, and often can be pipelined) and we can compute all the branch indexes just once, during the program initialization. Now, all that remains is to use the __sanitizer_cov_trace_pc_guard(uint32_t *guard) function to properly increment the value inside a given shared memory space, so at the end of the run we have the accurate representation of a trace.
When it comes to bitmap comparison is, again quite fast. In C we would simply write it like this:
memcmp(run1_bitmap, run2_bitmap, 65536) == 0`
Also, because the bitmap are of the same size and can be aligned in memory the compiler can turn this into super fast SIMD operations. My only issue with that approach is that we get a binary response - the coverage is either identical or it is now. Some time ago a friend of mine introduced me to the concept of location-sensitive hashing. In theory - and I am saying that only because I haven’t write the program yet - we can compute two hashes and calculate the Levenshtein distance between them. That would tell us how very different were the two runs we just observed. With that approach maybe we can actually capture the outlier runs and new branches bit better. Maybe that would be a good topic for the next article.